Imagine giving clear instructions to search engine crawlers with your robots.txt so your website’s way of speaking their language! Here is a guide on understanding how the robots.txt file works and how to use it to help prevent technical SEO problems on your website.
With a little bit of our help from Blue Sky Advertisement, let’s get a robots.txt file that works seamlessly with 2025’s SEO best practices.
Understanding Robots.txt

Purpose and Importance
The robots.txt file is a simple text file placed on your website’s server that communicates with web crawlers (also known as robots or bots). It tells them which pages or sections of your site should be crawled or ignored. This file is essential for:
- Controlling crawler behavior: Direct bots to the most important content.
- Protecting sensitive information: Prevent indexing of private or irrelevant pages.
- Optimizing crawl budget: Ensure search engines focus on valuable pages.
Impact on SEO
Proper configuration of your robots.txt file can significantly impact your site’s SEO by:
- Improving crawl efficiency: Helps search engines discover your content more effectively.
- Enhancing site ranking: By focusing crawlers on high-quality content, you improve your chances of ranking higher.
- Preventing duplicate content: Avoids indexing pages that could dilute your SEO efforts.
Basic Structure and Syntax
A standard robots.txt file consists of one or more blocks of directives, each starting with a User-agent line, followed by one or more Allow or Disallow lines.
Example:
User-agent: *
Disallow: /private/
Allow: /public/
Location Requirements
The robots.txt file must be placed in the root directory of your website (e.g., https://www.example.com/robots.txt). This is the first place crawlers look for instructions.
Creating Your Robots.txt File

File Creation Process
- Open a text editor: Use Notepad, TextEdit, or any plain text editor.
- Write your directives: Follow the correct syntax for your needs.
- Save the file: Name it robots.txt.
UTF-8 Encoding Requirements
Ensure your robots.txt file is encoded in UTF-8 without a Byte Order Mark (BOM). This encoding supports all characters and is universally accepted by crawlers.
Root Directory Placement
Upload your robots.txt file to the root directory of your domain. For example:
- Correct: https://www.example.com/robots.txt
- Incorrect: https://www.example.com/site/robots.txt
Proper Formatting Guidelines
- Use one directive per line.
- Separate blocks with a blank line.
- Start comments with a “#” symbol.
Essential Directives

User-Agent Specification
The User-agent directive specifies which crawlers the following rules apply to.
- User-agent: * applies to all crawlers.
- Specify a particular bot (e.g., User-agent: Googlebot) for targeted instructions.
Allow Directives
Use Allow to permit crawling of specific directories or files.
Example:
Allow: /public/
Disallow Directives
The Disallow directive blocks crawlers from accessing specified paths.
Example:
Disallow: /private/
Sitemap Directive
Including a Sitemap directive helps crawlers find all your site’s URLs efficiently.
Example:
Sitemap: https://www.example.com/sitemap.xml
Crawl-Delay Usage
The Crawl-delay directive sets a pause between requests to prevent server overload. Note that not all crawlers support this.
Example:
Crawl-delay: 10
Order of Precedence
Most Specific Rule Principle
When multiple rules apply, crawlers prioritize the most specific rule.
Example:
User-agent: *
Disallow: /images/
User-agent: Googlebot
Allow: /images/public/
In this case, Googlebot is allowed to crawl /images/public/ despite the general disallowance.
Least Restrictive Rule Application
Avoid overly broad Disallow directives that might block essential content.
Pattern Matching Hierarchy
Use wildcards (*) and end-of-line markers ($) for pattern matching.
- Disallow: /folder/* blocks all files in /folder/.
- Disallow: /page$ blocks only /page.
Multiple Directive Handling
Crawlers process multiple directives in order, so ensure your rules don’t conflict.
Common Configuration Examples
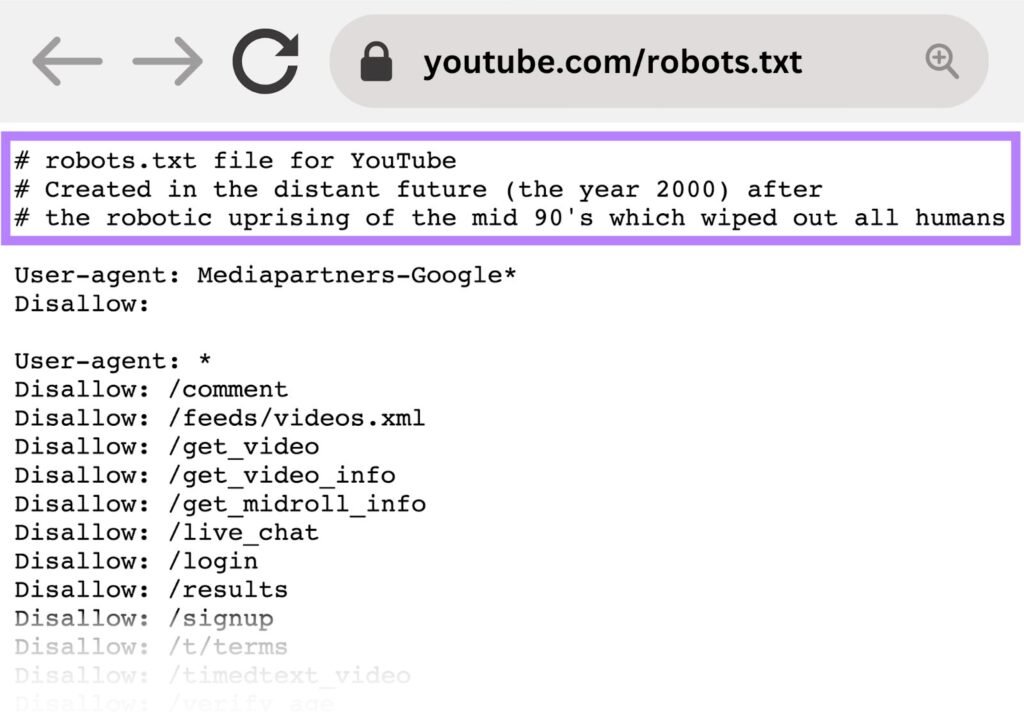
Blocking Internal Search Pages
Prevent indexing of search result pages to avoid duplicate content.
Example:
Disallow: /search
Managing Faceted Navigation
Control crawling of dynamic URLs with parameters.
Example:
Disallow: /*?*
Protecting Admin Areas
Keep administrative pages hidden.
Example:
Disallow: /admin/
Handling Media Files
Decide which images, videos, or documents to allow or block.
Example:
Disallow: /images/private/
Managing Subdomains
Each subdomain requires its own robots.txt file.
Advanced Configuration Techniques
Pattern Matching
Utilize wildcards for complex rules.
- * matches any sequence of characters.
- $ indicates the end of a URL.
Example:
Disallow: /*.pdf$
Blocks all URLs ending with .pdf.
Regular Expressions
While standard robots.txt doesn’t support full regex, some crawlers interpret patterns.
Multiple User-Agents
Provide specific instructions for different crawlers.
Example:
User-agent: Googlebot
Disallow: /no-google/
User-agent: Bingbot
Disallow: /no-bing/
Subdirectory Management
Fine-tune access to different site sections.
Protocol Considerations
Ensure your rules apply to both http and https by placing the robots.txt in both versions if necessary.
Best Practices

Single User-Agent Grouping
Group directives under relevant User-agent headings for clarity.
New Line Formatting
Use proper line breaks to separate directives.
Comment Usage
Add comments to explain configurations.
Example:
# Block admin area
Disallow: /admin/
Specificity in Rules
Be precise to avoid unintended blocking.
Separate Files for Subdomains
Each subdomain (e.g., blog.example.com) should have its own robots.txt.
Common Mistakes to Avoid
Blocking CSS/JavaScript
Blocking these resources can harm your SEO as crawlers may not render pages correctly.
Solution:
Make sure Disallow rules do not block /css/ or /js/ directories.
Using Noindex Incorrectly
Noindex is not supported in robots.txt. Use meta tags or HTTP headers instead.
UTF-8 BOM Issues
Avoid saving your robots.txt with a BOM, which can cause parsing errors.
Conflicting Directives
Review for overlapping rules that could confuse crawlers.
Improper File Location
Always place the robots.txt in the root directory.
Testing and Validation
Google Search Console Testing
Use GSC’s robots.txt Tester to validate your file.
Validation Tools
Third-party tools like Robotstxt.org Validator can help detect errors.
Monitoring Implementation
Regularly check your server logs and crawl stats.
Troubleshooting Issues
If pages aren’t indexed as expected, review your robots.txt for errors.
Regular Maintenance
Update your robots.txt as your site evolves.
A well-configured robots.txt file is a powerful tool in your SEO arsenal. By providing clear instructions to search engine crawlers, you make sure that your most valuable content gets the attention it deserves. Regular validation and updates are key to staying aligned with evolving SEO practices in 2025 and beyond.
Need help optimizing your website’s SEO? Contact Blue Sky Advertisement today!




